
3.1.6. Algoritma Seçimi
 Şekil 3.21. Algoritma Seçimi.
Şekil 3.21. Algoritma Seçimi.
Not. Dijital Eğitim Koordinatörlüğü. Creative Commons Lisansları (CC BY NC-ND)
Doğru algoritmanın seçimi, başarılı bir yapay zekâ çözümü oluşturmanın vazgeçilmez adımlarından biridir. Uygun algoritmanın belirlenmesi, modelin problem türü, veri özellikleri ve istenen iş sonuçları ile uyumlu olmasını sağlar. Bu karar, yalnızca modelin performansını değil, aynı zamanda ölçeklenebilirliğini, yorumlanabilirliğini ve genel verimliliğini de etkiler. Algoritma seçiminin temel ilkelerini anlamak, yapay zekâ sistemlerinin belirli zorlukları nasıl ele aldığını görmeye yardımcı olur. Bu durum, teknik ekipler ile kurumsal hedefler arasındaki uyumu artıran değerli içgörüler sunar.
Algoritma Seçimi Neden Önemlidir?
- Verimliliği Artırır
Doğru algoritmanın seçilmesi, hesaplama süresini ve kaynak kullanımını azaltır. - Doğruluğu Artırır
Algoritma ile problem türü arasındaki iyi bir uyum, güvenilir tahminler ya da sınıflandırmalar sağlar. - Aşırı ve Yetersiz Öğrenmeyi Önler
Aşırı öğrenme (overfitting): Modelin eğitim verisine fazla uyum sağlamasıdır.
Yetersiz öğrenme (underfitting): Modelin çok basit kalması ve yeterince öğrenememesidir.
Algoritma Türleri ve Uygunluğu
- Regresyon Algoritmaları
Sürekli çıktıları tahmin etmek için kullanılır (örneğin, satışlar ya da gelir).
Örnek: Bir yemek teslimat şirketi, günlük siparişleri tahmin etmek için doğrusal regresyon kullanabilir. - Sınıflandırma Algoritmaları
Verilere etiketler atar (örneğin, spam veya spam olmayan).
Örnek: Lojistik regresyon, bir müşterinin hizmeti bırakıp bırakmayacağını tahmin etmekte kullanılabilir. - Kümeleme Algoritmaları
Benzer veri noktalarını gruplar ve kalıpları ortaya çıkarır.
Örnek: K-Ortalamalar (K-Means), farklı müşteri gruplarını belirlemeye yardımcı olabilir. - Derin Öğrenme Algoritmaları
Görüntüler ve konuşmalar gibi karmaşık, yüksek boyutlu verileri işler.
Örnek: Konvolüsyonel sinir ağları (CNN), yüz tanıma sistemlerinde kullanılır. - Boyut Azaltma Yöntemleri
Yüksek boyutlu verileri daha kolay analiz için sadeleştirir.
Örnek: Temel bileşenler analizi (PCA), genom verilerinde en önemli değişkenleri ortaya çıkarabilir.
Ölçeklenebilirlik ve Karmaşıklık
- Basit Algoritmalar
Küçük veri setleri ve temel görevler için uygundur. - Karmaşık Algoritmalar
Derin öğrenme algoritmaları büyük veri setlerinde yüksek doğruluk sağlar ancak GPU gibi güçlü donanımlar gerektirir.
Örnek: CNN algoritması, milyonlarca etiketli görsel üzerinde görüntü tanıma modeli eğitmek için kullanılır. - Dağıtık İşlem Çerçeveleri
Apache Spark ve Hadoop gibi sistemler, hesaplamaları kümelere dağıtarak büyük veri işlemlerini kolaylaştırır. - Basitlik ve Performans Arasındaki Denge
Kaynakların sınırlı olduğu durumlarda daha basit algoritmalar tercih edilebilir. Bu algoritmalar biraz daha az doğru olabilir, ancak uygulanmaları daha kolaydır.
Sonuç
Doğru algoritmanın seçimi, bilimsel analiz ile alan uzmanlığının birleşimini gerektirir. Problemin, verinin ve hedeflenen sonuçların iyi anlaşılması bu sürecin temelini oluşturur. Algoritma seçimi, bir yapay zekâ projesinin başarısını belirleyen başlıca faktörlerden biridir.
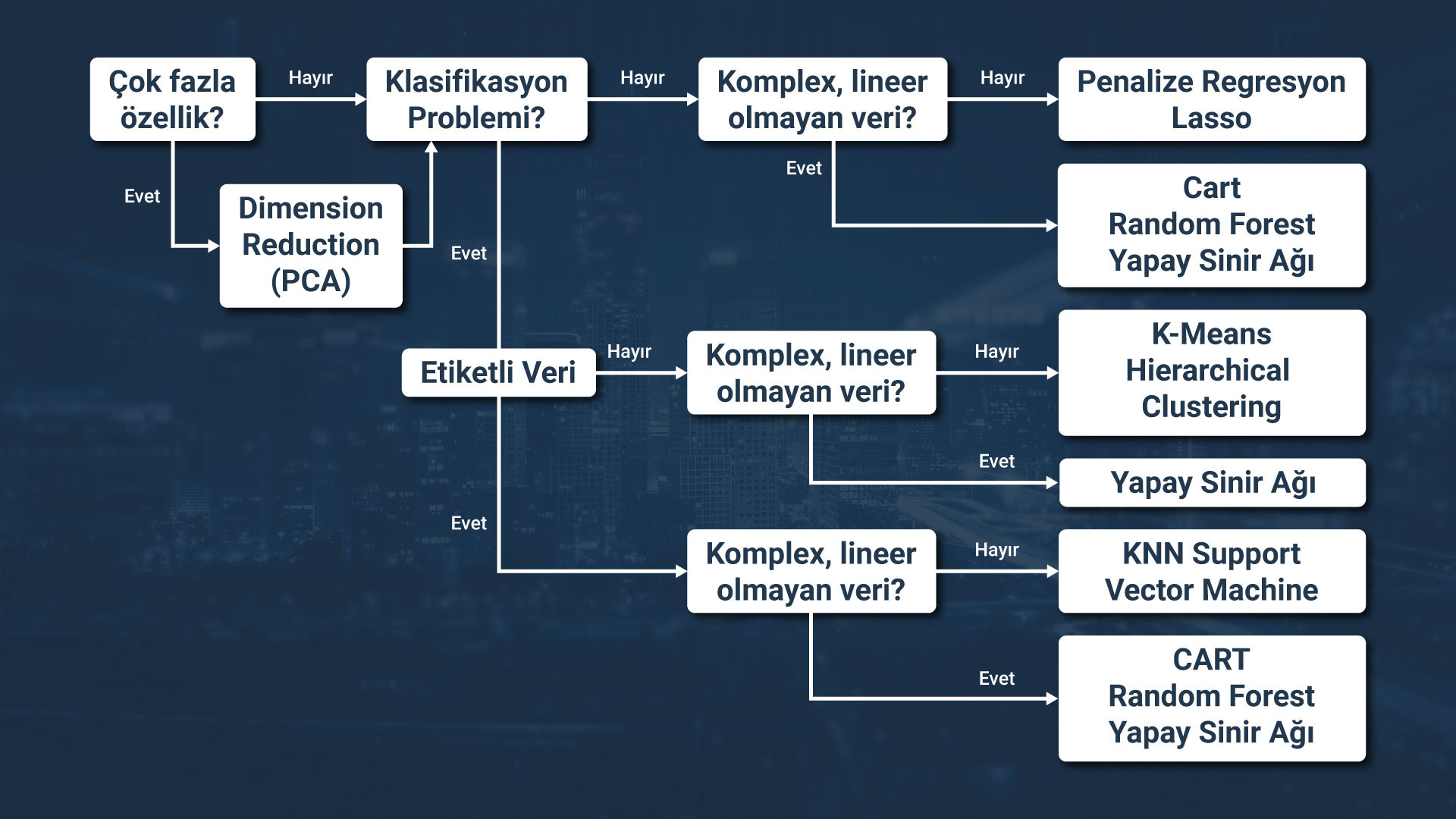 Şekil 3.22. Algoritma Seçim Diyagramı.
Şekil 3.22. Algoritma Seçim Diyagramı.
Not. Dijital Eğitim Koordinatörlüğü. Creative Commons Lisansları (CC BY NC-ND)
